By: Cristian Diaz, Hao Kang, John Nguyen, James Zhang
About The Research Paper The research paper we took a look at is "Don't Decay the Learning Rate, Increase the Bach Size" by Samuel L. Smith∗ , Pieter-Jan Kindermans∗ , Chris Ying & Quoc V. L.
In this paper they did used a stochastic gradient descent (SGD) to test whether to decay the learning rate or increase the batch size. They decided on a SGD with momentum because it is more commonly used in the field. In their paper they proved mathematically and empirically that increasing the batch size produces the same result as reducing the learning rate for accuracy results. The big take away is that they can increase the batch size without needing to tune hyper-parameters. Link: https://arxiv.org/pdf/1711.00489.pdf |
|
|
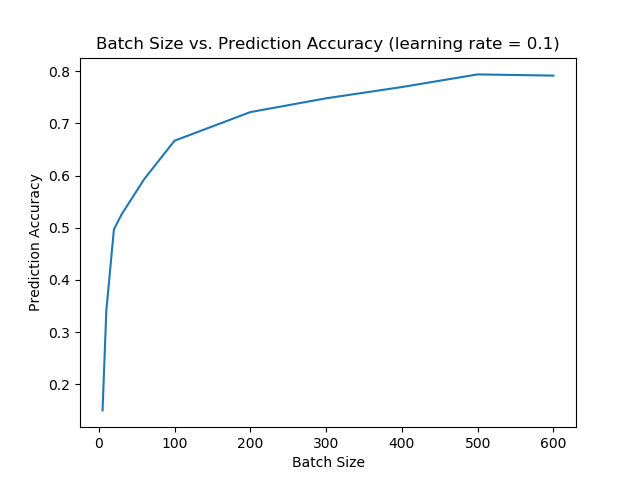
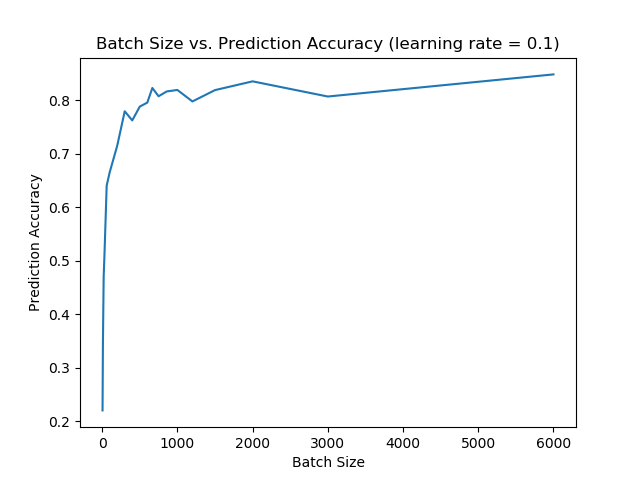
We ran the SGD model several times on the data to achieve multiple trials. Our trials with changing the batch size correlated to their research paper. When we had increased the batch size while maintaining a constant learning rate the prediction accuracy would increase.
|
|
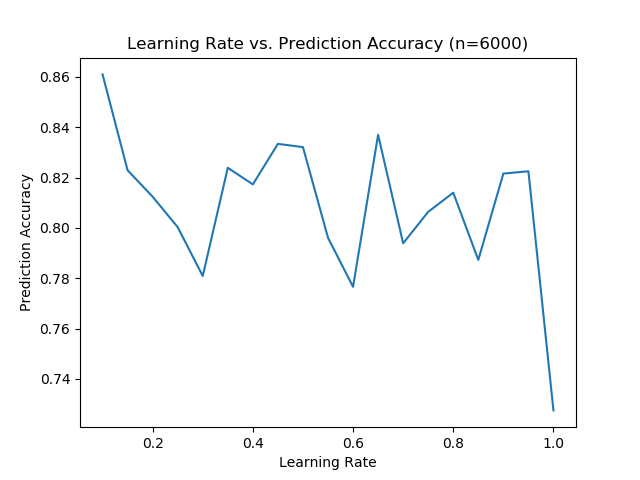
When we were testing the learning rate a much more interesting result appeared. When we change the initial learning rate there appears to be very little correlation between learning rate and prediction accuracy. However this was slightly different from the experiment the paper implemented. They utilized an adaptive learning rate that changes throughout the learning process where the learning rate decreases by a factor of 5 after a sequence of "steps"
We did run a sequence of trials the same way that they did in their experiment. In SK learn we can set the learning_rate='adaptive' which decreases the learning rate by a factor of 5 after hitting a stopping criterion. While we are not sure this perfectly emulates what the research paper is attempting we do believe that is achieves relatively the same thing.
We did run a sequence of trials the same way that they did in their experiment. In SK learn we can set the learning_rate='adaptive' which decreases the learning rate by a factor of 5 after hitting a stopping criterion. While we are not sure this perfectly emulates what the research paper is attempting we do believe that is achieves relatively the same thing.
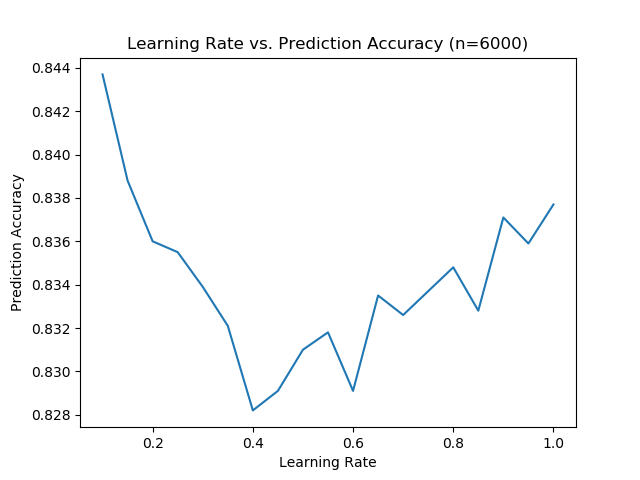
This graph was produced using the adaptive learning rate that they utilized during the research paper. The graph looks rather wonky because it has a high prediction accuracy with a extremely high learning rate. It appears that when the learning rate is a high enough number there is a lot of variance with the resulting prediction accuracy.
However the learning rate below 0.4 follows exactly what we expect. With a decreasing starting learning rate the prediction accuracy increases.
However the learning rate below 0.4 follows exactly what we expect. With a decreasing starting learning rate the prediction accuracy increases.
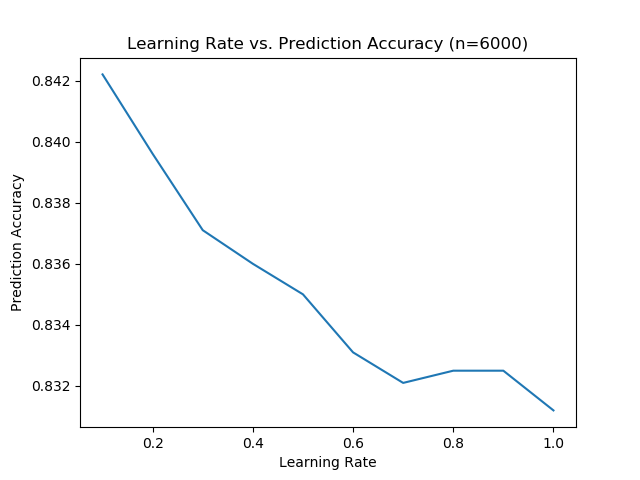
After running the code again to get another trial done it looks like the whole graph follows what we expected. With a decreasing starting learning rate the prediction accuracy increases.
The difference between our two graphs would tell us that prediction accuracy can be extremely volatile. This might mean that more trials are needed to determine the overall validity of our results.
The difference between our two graphs would tell us that prediction accuracy can be extremely volatile. This might mean that more trials are needed to determine the overall validity of our results.
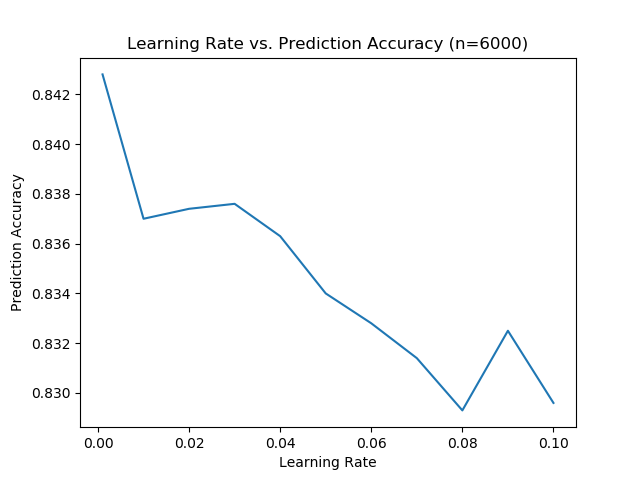
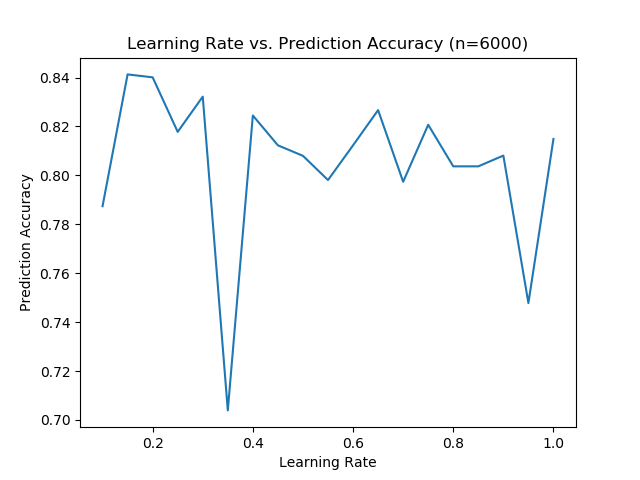
We performed another trial but we changed the initial learning rate range. We had the learning rate range from 0.001 - 0.1 instead of 0.1-1.00 in the previous two graphs.
Note how at 0.1 this graph tells us the prediction accuracy was around a 0.83 while in the previous graphs it was much closer to a 0.84. Despite having a different range with the learning rate the prediction accuracy still followed the same values and trends as the other two graphs. This reinforces the idea that the prediction accuracy is imprecise.
Note how at 0.1 this graph tells us the prediction accuracy was around a 0.83 while in the previous graphs it was much closer to a 0.84. Despite having a different range with the learning rate the prediction accuracy still followed the same values and trends as the other two graphs. This reinforces the idea that the prediction accuracy is imprecise.
Conclusion
The increase in batch size shows similar results to the research paper we were looking at. With an increase in batch size we witnessed an increase the prediction accuracy.
When we attempted to emulate the learning rate decay we saw results that looked similar to the paper but there were inconsistencies. The biggest example was how imprecise the prediction accuracy was with the same learning rates. What likely needs to be done next is running the model repetitively and then performing some statistical analysis on the resulting data set. Even something as simple of taking the average for each learning rate across multiple runs will likely lead to more consistent results than the ones we saw earlier.
When we attempted to emulate the learning rate decay we saw results that looked similar to the paper but there were inconsistencies. The biggest example was how imprecise the prediction accuracy was with the same learning rates. What likely needs to be done next is running the model repetitively and then performing some statistical analysis on the resulting data set. Even something as simple of taking the average for each learning rate across multiple runs will likely lead to more consistent results than the ones we saw earlier.
Relevant Background Papers
https://arxiv.org/pdf/1412.6980.pdf
ADAM: One potential option for optimizing gradient descent stochastically.
https://arxiv.org/pdf/1511.06251.pdf
A report on stochastically modified equations (SMEs)
ADAM: One potential option for optimizing gradient descent stochastically.
https://arxiv.org/pdf/1511.06251.pdf
A report on stochastically modified equations (SMEs)
Code
We utilized SK Learn's Stochastic Gradient Descent in our code.
https://scikit-learn.org/stable/modules/sgd.html
The dataset we used is the MNIST Database.
http://yann.lecun.com/exdb/mnist/
We utilized this to process the dataset from MNIST Database.
https://pypi.org/project/python-mnist/
Our Github repository which contains the code we utilized.
https://github.com/johnhoangn/Machine-Learning-Final-Project
https://scikit-learn.org/stable/modules/sgd.html
The dataset we used is the MNIST Database.
http://yann.lecun.com/exdb/mnist/
We utilized this to process the dataset from MNIST Database.
https://pypi.org/project/python-mnist/
Our Github repository which contains the code we utilized.
https://github.com/johnhoangn/Machine-Learning-Final-Project
